Differential privacy and the secrecy of the sample
(This post was laid out lazily, using Luca‘s lovely latex2wp.)
— 1. Differential Privacy —
Differential privacy is a definition of “privacy” for statistical databases. Roughly, a statistical database is one which is used to provide aggregate, large-scale information about a population, without leaking information specific to individuals. Think, for example, of the data from government surveys (e.g. the decennial census or epidemiological studies), or data about a company’s customers that it would like a consultant to analyze.
The idea behind the definition is that users–that is, people getting access to aggregate information–should not be able to tell if a given individual’s data has been changed.
More formally, a data set is just a subset of items in a domain 
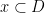

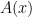
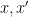

Definition 1 A randomized algorithm
-differentially private if, for all pairs of neighbor data sets
in the output space of

This definition has the flavor of indistinguishability in cryptography: it states that the random variables 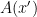
I hope to write a sequence of posts on differential privacy, mostly discussing aspects that don’t appear in published papers or that I feel escaped attention.
— 2. Sampling to Amplify Privacy —
To kick it off, I’ll prove here an “amplification” lemma for differential privacy. It was used implicitly in the design of an efficient, private PAC learner for the PARITY class in a FOCS 2008 paper by Shiva Kasiviswanathan, Homin Lee, Kobbi Nissim, Sofya Raskhodnikova and myself. But I think it is of much more general usefulness.
Roughly it states that given a 
Suppose 

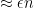
Algorithm 2 (Algorithm
and a multi-set
- Construct a set
by selecting each element of
independently with probability
- Return
.

Lemma 3 (Amplification via sampling) If
,
is
-differentially private.
Proof: Fix an event 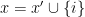
Consider a run of 

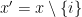

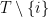
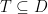
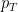
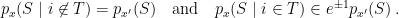
We can put the pieces together, using the fact that

We can get a similar lower bound:

The last inequality uses the fact that 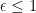

Notes on the proof: (a) I did not attempt to optimize constants. (b) We don’t need a lower bound on 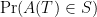
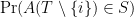

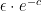

— 3. Interpretation: The Secrecy of the Sample —
The amplification lemma works by sampling a random subset of the input and so it makes the most sense to apply it in settings where the input is itself a random sample from some underlying population. The price, then, of amplifying
There is a different interpretation, however, which I like more. It says that if you are doing a survey and you can reasonably expect that the sample itself will remain secret, then you get
— 4. Update: Proving the lemma with a weaker hypothesis —
Omkant in the comments asked about proving the lemma with only an upper bound on 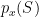
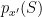
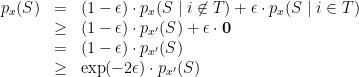
The last inequality holds as long as 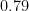

Quite cool. The “secrecy of the sample” interpretation is actually what I liked the most. Btw, could you elaborate more on why we don’t need the lower-bound to conclude the lemma?
Omkant
September 7, 2009 at 5:28 am
Updated to add the details.
adamdsmith
September 7, 2009 at 8:44 am
Ahh… I believe I got confused with the statement “we don’t need lower-bound….”. You were saying that we don’t need to use the lower-bound coming from A being 1-dp (so 1/e * pr) to conclude the other direction. I took it as if we did not need to conclude the lower-bound itself in your proof of Lemma 3.
Omkant
September 7, 2009 at 5:46 pm
More posts please…
Anonymous
October 4, 2009 at 5:52 am
[…] Rubenstein has a nice post on the differential privacy model, and Adam Smith has more to say on sample secrecy. Adam and his colleagues were helpful in pointing out some bugs in an earlier version of our proof, […]
Differentially Private ERM « An Ergodic Walk
June 4, 2010 at 3:49 pm